个人博客:haichenyi.com。感谢关注
1. 目录
- 1–目录
- 2–简介
- 3–getSharedPreferences会不会阻塞线程,为什么?
- 4–get操作,为什么有时候会卡顿?
- 5–commit和apply的区别
- 6–sp写入异常会怎么处理?
- 7–优化sp操作
2.简介
从工作开始,Android存储数据最常见的应该就是SharePreference,但是,你真的用懂了吗?源码你看过吗?Google对sp的定位你知道吗?是不是所有数据都应该用sp来存储呢?
为什么现在面试关于sp非常常见呢?不就是一个get,put键值对的东西吗?commit或者apply就提交存储了,这么简单的一个东西,有啥好问的?
腾讯的mmkv,Google的dataSorce又是什么东西呢?
先说说sp,Google对sp的定位是轻量级存储,轻量级是什么意思呢?数据量小,数据量大肯定不建议用,但是,往往很多程序员,不管三七二十一,全都是用sp做本地持久化,导致,或多或少的性能问题,当然,不可否认sp的设计也有它的弊端。
sp 加锁多 xml解析 全量更新 速度慢 性能差 提交数据可能会ANR
3.getSharedPreferences会不会阻塞线程,为什么?
下面从用法一步一步来讲解sp的问题
1 | SharedPreferences sp = getSharedPreferences("haichenyi", MODE_PRIVATE); |
上面这个是获取sp,第一个问题就来了,我们都知道获取sp这里是从磁盘读取数据,就是从文件中读取数据,我们一般从文件中读取数据都是要新开线程的,这里没有新开线程,会不会阻塞主线程,为什么?带着这个问题,我们往下走。

这里调用的是base的getSharedPreferences方法,我们看这个base的类型,会发现是Context类型的,Context我们都知道,是装饰者模式,它的实现类ContextImpl,我们到这个类里面区找上面的这个方法,如下图
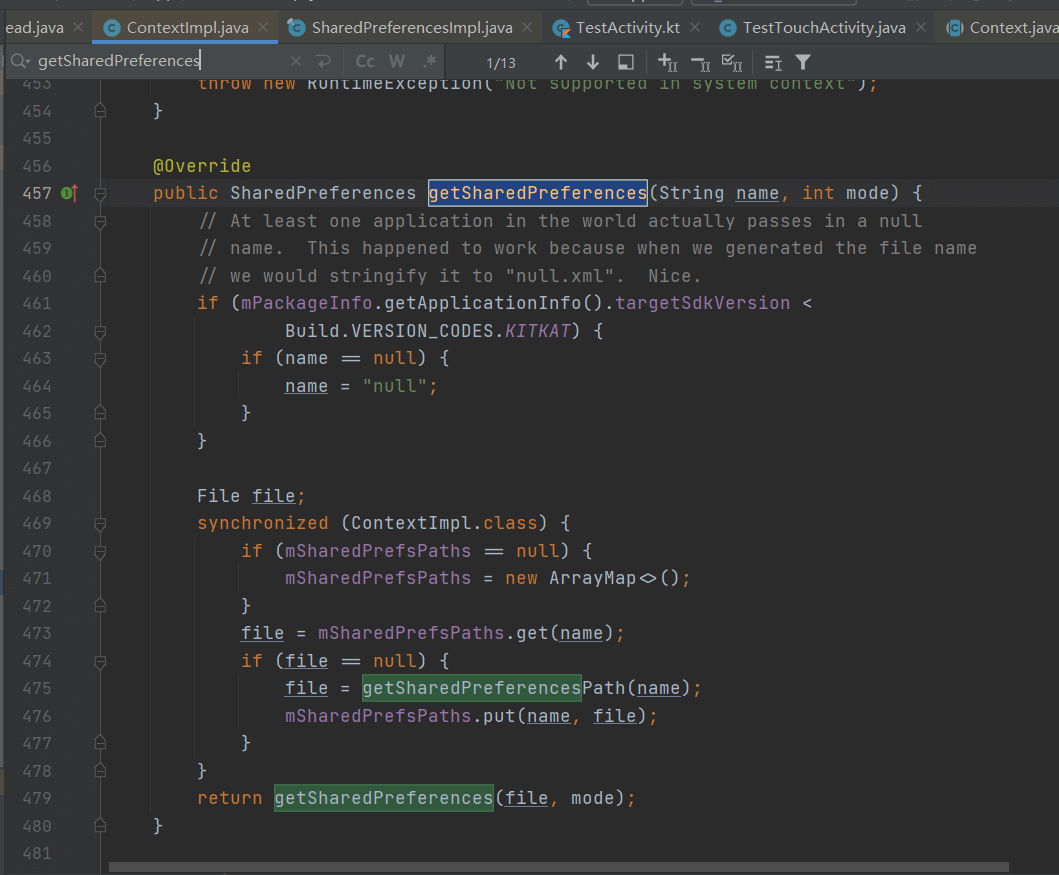
这个里面逻辑并不复杂,就是一个name在 api19以下的空判断,然后就是file的空判断,用的ArrayMap存储,最后就是调用的重载方法,如下图
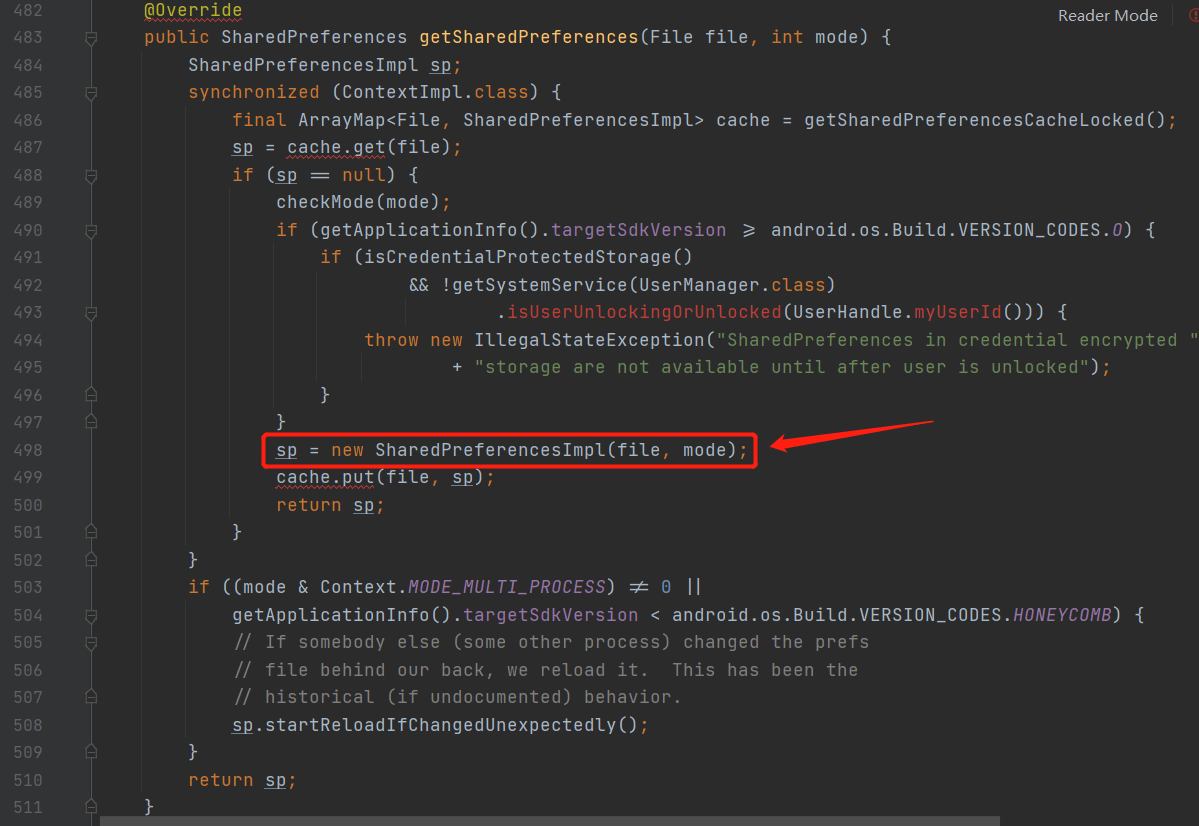
重点就是框起来的这里了,SharedPreferences的实现类SharedPreferencesImpl,这里也是装饰者模式(到处都是)。
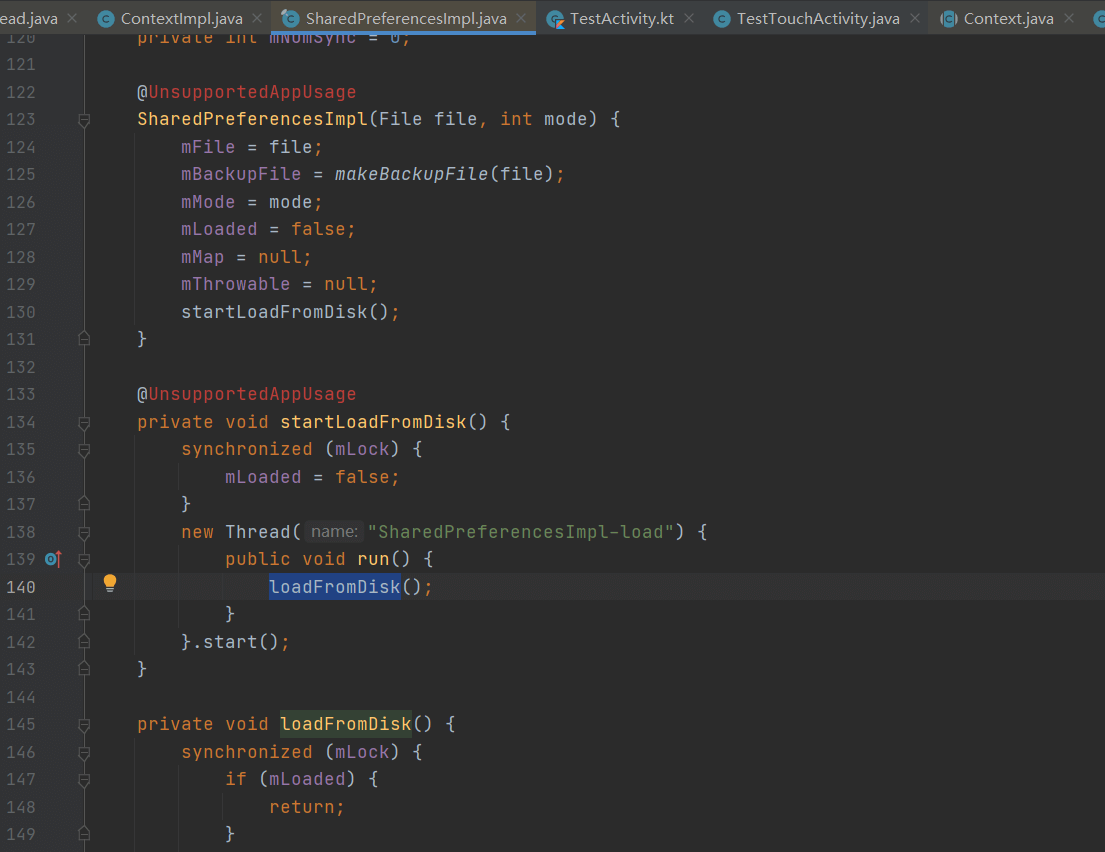
看到这里就知道了,它的startLoadFromDisk方法,看名字就知道是从磁盘读取数据,这里有个synchronized锁,锁对象是mLock,这个mLock比较重要。里面有一个mLoaded的Boolean类型的值,它也比较重要。下面具体读数据的逻辑,loadFromDisk是新开线程读取的。
所以,我们回到前面的问题会不会阻塞线程?虽然,它是同步返回的sp对象,但是,具体读数据的逻辑是新开线程的,所以,不会阻塞线程。
4.get操作,为什么有时候会卡顿?
会卡顿吗?怎么没有碰到过呢?答案是肯定的,肯定会有卡顿的情况,这是为什么呢?我们来看看它的实现:
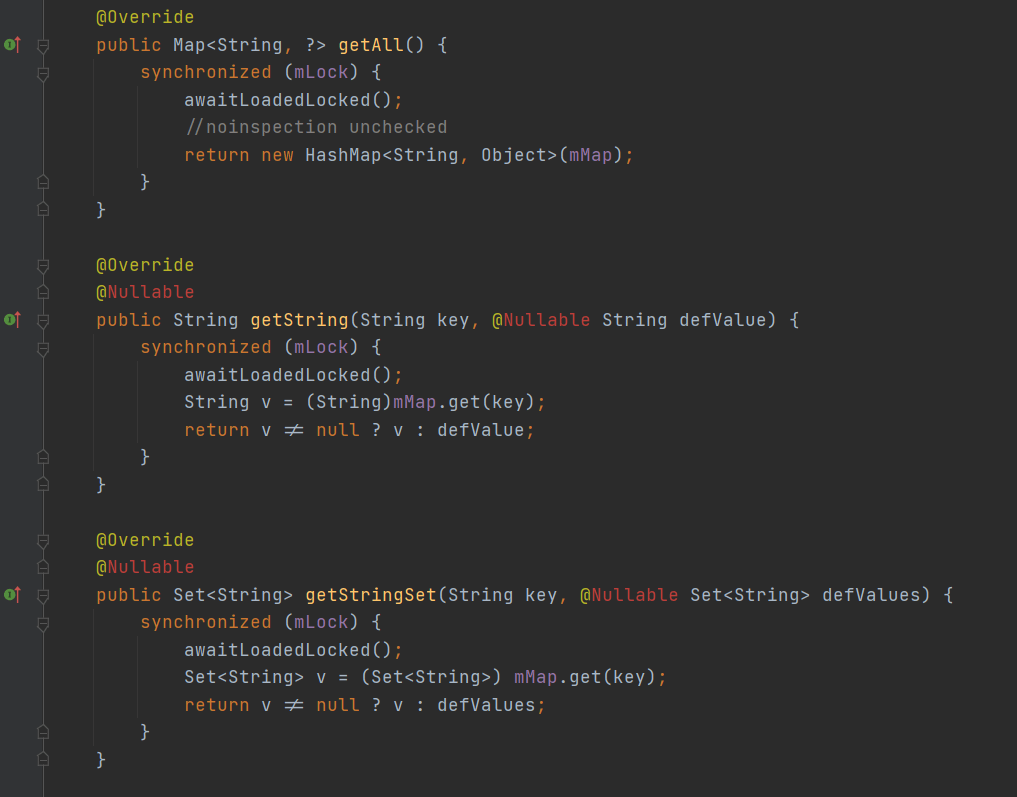
我们来看看这个getXXX这一系列的方法,里面都有同步锁,然后,都有一个awaitLoadedLocked方法,重点就是这个方法,看名字就知道:等待加载锁。什么意思呢?我们看一下具体实现
1 | private void awaitLoadedLocked() { |
这里有一个while循环,判断的就是上面我们提到过的mLoaded,然后,里面就是我们上面也提到过的mLock对象,mLock.wait()方法。
当代码执行到这里的时候,如果mLoaded是false,就会进入while循环,然后,会调用mLoack的wait方法,进入等待状态。
那,这个mLoaded的值又是在哪里修改的呢?mLock对象是时候唤醒呢?
我们回到上面说的,新开线程执行loadFromDisk方法
1 | private void loadFromDisk() { |
源码里面注释都写的比较清楚。mLoaded值的修改是在从磁盘中把数据读取完之后,然后,在finally里面调用notifyAll唤醒mLock。
数据读完之后,修改boolean值,然后,在finally里面唤醒,finally是try-catch最后执行的。
为什么会卡顿呢?我们平时用sp,是不是像下面这样用的:
1 | //这里是直接返回对象, |
上面代码的注释写的很清楚了吧?不用在做过多的解释了吧?
PS:它这个卡顿仅限于第一次,为什么呢?因为它从磁盘读出数据之后,把数据存到内存中了(也就是loadFromDisk方法中的mMap对象),我在那里加了注释,可以去看一下。读取数据都是从这个mMap对象返回的,也就是从内存中返回,这也是为什么从另一方面说,sp返回数据比较快的原因。它都是从内存中返回的,并不是每次都是从磁盘读数据,然后返回的。
5.commit和apply的区别
先说结论:
| 类型 | 返回值 | 同步 | ANR |
|---|---|---|---|
| commit | 有 | 同步提交 | 可能会 |
| apply | 无 | 异步提交 | 可能会 |
我们一个一个来慢慢说这个结论:
是否有返回值
这个很简单吧?用过如果没注意,可能不知道,因为,我们平时也不用处理这些东西,我们来看一下源码就知道了。
1 | //看到这个方法有返回值就知道了,boolean类型的返回值 |
我们先说返回值的问题,上面这两个方法就是commit和apply的大致结构。所以,commit是有个boolean类型的返回值,apply是没有返回值的
是否有同步
这个问题,上面commit的源码注释那里已经解释清楚了,它会有一个wait方法等待数据更新完,所以commit是同步的。
我们再来看看apply方法,上面主要是说返回值的问题,所以,没有把apply的源码贴出来,下面我们来看看apply的源码
1 | public void apply() { |
我这里的源码解释的是比较清楚的了吧?所以,apply是异步的。
是否会ANR
说到ANR,我们先来聊一下ANR,什么是ANR?多长时间会造成ANR提示?
ANR:Android系统是消息驱动的,每个消息都需要在一定的时间范围内处理完,如果在规定的时间内未处理完,系统就会提示ANR异常
那么,这个时间是怎么限定的呢?
| 类型 | Service | Broadcast | Activity | ContentProvider |
|---|---|---|---|---|
| 前台(单位:s) | 20 | 10 | 5 | 10 |
| 后台(单位:s) | 20*10 | 60 | - | - |
前两个都好理解,这个ANR就很难理解了,commit是同步提交,可能会ANR我可以理解,sp每次都是全量更新,commit又是在主线程提交,cpu峰值的时候,数据量大,可能就会卡住主线程,造成ANR。
辣么,问题就来了,commit同步卡能会卡住主线程,造成ANR,apply是异步的呀?为什么apply也会造成ANR呢?是结论错了吗?
龙儿筝给我说了一个结论:Google认为SP是数据持久化,数据的安全性要大于页面的行为,当页面离开时,会等待持久化完成。
这个结论怎么理解呢?有一个场景,当你调用apply去更新数据,然后,紧接着下一行代码就执行了finish方法,或者跳转了下一个界面,此时会怎么样呢?
我们先来简单聊一聊activity启动相关的问题
简单的从AMS开始说两句吧,当zygote进程启动了系统主要的服务之后,里面就有一个AMS(ActivityManagerService),AMS通过Binder创建了ActivityThread,然后通过handler开始发消息,创建Activity,我们activity的生命周期的回调,都说是系统调用了,系统是怎么调用的呢?都是通过handler发送一个一个的消息,然后去执行对应的回调方法。
然后,再是,我们常说的onCreate—onStart(可见,不能与用户交互)—onResume(可见,与用户交互)—activity running—onPause—onStop—onDestroy
除了activity running,其余的每一种生命周期都对应着一个handler的message。handler的机制,在我的博文深入理解handler机制里面讲的很清楚了
辣么,从Activity A跳转Activity B,两个activity的生命周期是怎么变化的呢?
当A中启动B,生命周期的流程是这样的:
- A的onPause
- B的onCreate-onStart-onResume
- A的onStop
扯了这么远,回到上面说的apply的问题,为什么它会ANR线程呢?
问题就出在这个A的onStop方法里面,我们来看看这个onStop放的源码:
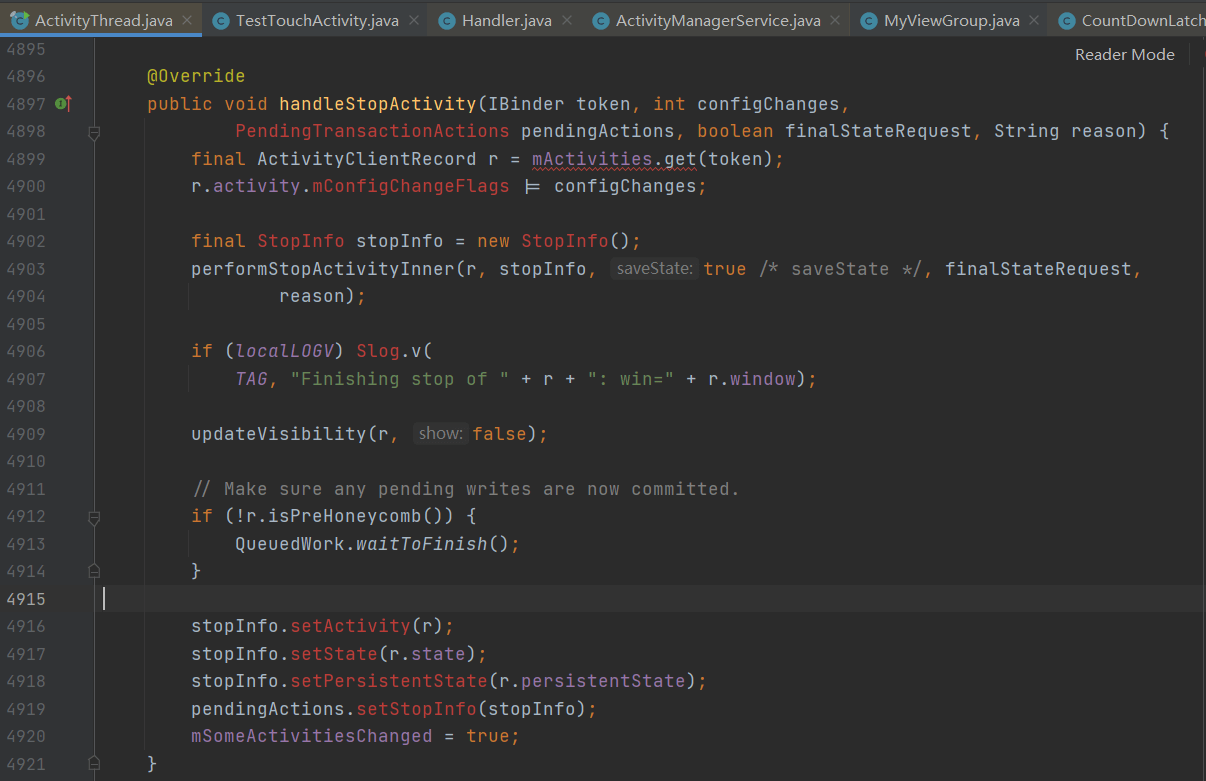
如上图,我们通过handler发送消息,最终定位到执行的是这一块的代码,看到我框起来的代码了吗?
1 | // Make sure any pending writes are now committed. |
上面的注释很清楚了,这个waitToFinish方法里面的逻辑是什么样的呢?大致贴一下主要的逻辑:
1 | public static void waitToFinish() { |
我们想想之前apply方法里面,是不是新建的runnable,然后,把这个runnable是不是添加到sFinishers队列中去了?
所以,整个逻辑就是
- 你在Activity A中apply之后(假设数据量大),立马跳转Activity B
- 当Activity B正常启动完,走完它自己的onResume方法,执行了Activity A的onStop方法
- 执行的时候发现,QueueWork里面还有提交正在执行,就会等待它执行完,就会阻塞当前线程
6.sp写入异常会怎么处理?
在代码执行getSharedPreferences的时候,你会发现,磁盘上会多一个同名文件,扩展名不一样,扩展名是 点bak,这个文件是备份文件。写入成功就会删除这个文件,写入失败,下次就会用这个备份文件。
我们再来找一下源码你会发现:
1 | static File makeBackupFile(File prefsFile) { |
这个方法在哪调用的呢?在SharedPreferencesImpl的构造方法里面
1 | SharedPreferencesImpl(File file, int mode) { |
我们再来看看这个写入方法,你会发现,在写入完成之后,会把这个文件删除
1 | private void writeToFile(MemoryCommitResult mcr, boolean isFromSyncCommit) { |
7.优化sp操作
- sp获取的时候,会新开线程去读取数据,我们可以提前读取sp,不要每次到用的时候,再去读取。
- sp每次提交都是全量更新,不要每次修改了就直接提交,可以多修改几次之后,一起提交
- sp是轻量级存储,数据量大,不要存sp
- sp的内容不要太多,sp内容过多,读取的时候会非常慢,可以适当的拆分sp的内容,分多个sp存储,但是也不要太多
但是,这些优化操作,都是基于sp原有的性能做的优化操作,不能从根本上解决问题。
sp的源码就说完了,为什么Google更新了十多版本之后的sp,最终还是放弃维护了?而是新出推出了Jetpack的组件之一DataStore这是人性的扭曲还是道德的沦丧,我们且听下回分解。
下一篇来聊聊MMKV,它是怎么从根本上解决问题的。