用了好几年的dagger2,从dagger2.android。就只有当时刚开始用dagger的时候深入的了解过,后来就再也没有深入的时候研究过。这几天又研究了一下,做个总结。
就拿之前写的kotlin的框架来说,它用的是dagger2.android。从dagger2.android。最明显的就是,需要我们自己写的东西越来越少了,框架帮我们做的事情越来越多了,以至于,我们对这个过程越来越看不懂了。也就有了我这篇博客。
先说这嵌入过程吧。
1.依赖
1 | //dagger2_start |
2.DaggerApplication
新建类AppMoudle,并用注解@Moudle标记,暂时先不添加任何内容
1 | @Module |
新建接口AppComponent,并实现AndroidInjector
1 | @Singleton |
这里的MyAPP是我们下面新建的Application
新建MyApp,继承DaggerApplication并实现它的抽象方法,添加如下代码:
1 | class MyApp : DaggerApplication() { |
这个时候,你的项目应该报错,因为你没有DaggerAppComponent这个类,你现在编译一遍,应该就是能生成
DaggerAppCompatActivity
让你的BaseActivity类,继承这个DaggerAppCompatActivity
新建ActComponent接口,并且实现AndroidInjector
1 | @Subcomponent(modules = [AndroidSupportInjectionModule::class]) |
新建AllActivityModule类,添加如下代码:
1 | @Module(subcomponents = [ActComponent::class]) |
这个MainActivity是你的主页面,并且继承你的BaseActivity。
至此,配置就完成了,你就可以像之前一样,用@Inject标记构造方法,然后,定义变量的地方用@Inject就可以直接用了。
PS: 我这里用的kotlin,kotlin参数默认是private,dagger2需要参数是public,这里需要加上JvmField注解。并且,要var类型,不能val,因为,val不能二次赋值。如下:
1 | @JvmField |
我们之前用dagger2,没有用dagger2.android的时候,application和activity并不是实现的DaggerApplication,DaggerAppCompatActivity这两个,我们做了很多额外的操作,现在,我们都没有做了,为什么一样可以能运行?因为,我们之前做的额外的操作,现在都是这两个继承的类帮我们做了,可以点进去看一下源码。
引发的思考
如标题,引发的思考是什么呢?它这个注解到底是怎么做到的呢?
问,这里为什么会分AppComponent,ActivityComponent,FragmentComponent,写一个component不好吗?
答: 我不知道对不对,我的理解是:与整个APP生命周期同步即放在AppComponent中,与Activity生命周期同步即放在ActComponent中,
与Fragment生命周期同步即放在FragComponent中。
从这里引申出什么问题呢?那就是生命周期,我的kotlin框架整个生命周期都有处理,框架的README也有说明。说到生命周期同步,就要说到不同步,不同步造成的结果就是内存泄漏,至于常见的什么情况下回造成内存泄漏我就不说了,想到内存泄漏,就联想到了内存,想到内存,我就想到了内存分配。这就是我想说的,内存分配。
内存分配
说到内存分配,我们就先说三个名词:栈,堆,方法区
- 栈:存放变量的引用
- 堆:存放new的对象,堆是最占内存的
- 方法区:存储字节码信息(类,方法等等字节码),常量,静态变量等等。常量池在方法区中
举个栗子:String b = new String(“a”) 和 String c = “a”,他们内存是怎么分配的?如图:
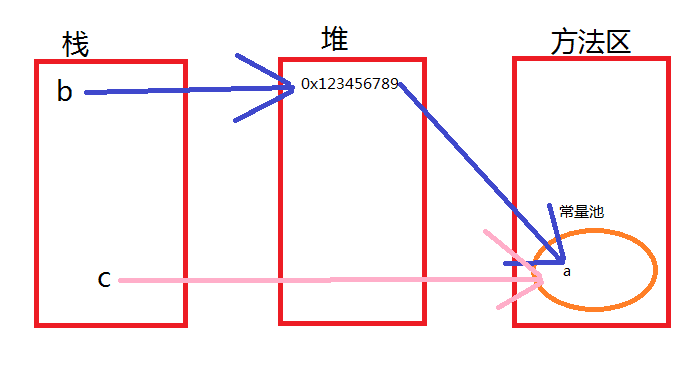
- 等于号左边 String b,String c这里的b,c都是引用,所以放在栈中。栈存放引用
- 等于号右边,new的过程,就是在堆中创建内存的过程,这里的0x123456789就是我们常说的内存地址
- 常量池里面才是放字符串a
很多面试题都会出这个问题,b==c和b.equal(a) ,他们两个的结果结果都知道,前面是false,后面是true。== 比较的是整个对象,而equals比较的是值。这里b指向的是堆内存中的地址,这个地址才是指向常量池中的字符串a,而c是直接指向常量池中的字符串a
想多说一句就是 == 是怎么比较物理地址的呢?通过比较hashCode的值,在java中是获取不到地址的,不过Object中有个identityHashCodeNative方法,它虽然不是地址,但你可以理解为一个地址对应一个值,这个值就能过identityHashCodeNative来获取,具体怎么算了,这是个native方法我们不知道。不过没关系,只要知道一个地址对应一个值就行了,地址相同这个值就相同。而hashCode默认就是返回这个值,那么如果我们重写了hashCode,按我们的规则来写,可以达到不同的地址,hashCode的值相同,从而得到两个不同的地址用==比较是相同的。
PS: 我们平时说的 把某某对象置为空,释放内存。这种说法是错误的。 比方说这里,b=null,首先,我们只是把某个对象的引用置为空,并不是把某个对象置为空。释放内存,是java的GC回收机制,释放内存,并不是我们释放内存。当GC扫描到,某个对象没有引用指向它了,它就会释放这个对象占用的内存。说到这里,就又想到GC回收机制与强软弱虚四大引用
GC回收和强软弱虚四大引用
强软弱虚四大引用
其实我也不知道说啥,就是上面理解了内存分配,这里再看这几句话,应该印象更加深刻一些。
- 强引用:不论什么情况下,GC回收机制扫描到强引用,都不会管,如果内存不足,则抛出OOM异常
- 软引用(SoftReference):GC回收机制扫描到软引用时,当内存足够的时候,不会管,当内存不足的时候,则会回收对应内存
- 弱引用(WeakReference):不论什么情况下,只要GC回收机制扫描到弱引用,都会回收对应的内存。
- 虚引用(PhantomReference):顾名思义,形同虚设,前面三种都是与生命周期相关,而虚引用不会决定对象的生命周期,如果,一个对象仅持有虚引用,那这个对象就跟没有引用是一样的,不管什么时候,GC回收机制扫描到了这个对象,都有可能会回收对应的内存。为什么说是有可能呢?虚引用必须和引用队列连用,当GC回收机制扫描到一个对象,并准备回收它的时候,发现它还存在虚引用,那么,GC会把这个虚引用先加入到与它关联的引用队列中。所以,当GC发现一个对象有虚引用,并且,这个虚引用已经存在与之关联的引用队列当中了,就会回收这个对象。
GC回收机制判断是否回收内存,都是先判断对象的引用是否存在,引用存放在栈中。
GC回收机制
说到GC回收机制,就先聊聊JVM堆的相关知识,一说要JAVA虚拟机,那就要聊聊java是跨平台语言了,它是怎么实现跨平台的呢?
java程序是跨平台的语言,它是怎么实现跨平台的?
java程序依赖于JVM(java虚拟机),java程序必须运行在JVM上,JVM是用C、C++开发的,不同的平台是不同的JVM,但是,不管是什么类型的JVM都能运行java程序,这就是所谓的java跨平台。但是,不同JVM编译java程序生成的字节码是一样的,但是编译生成的机器码是不一样的,所以跨平台的是java程序,而不是编译生成的机器码。
JVM堆,也就是我们上面那个图的堆,JVM堆分为三部分
- 新域:也就是年轻代,分为三部分,一部分:Eden,另两个部分是辅助空间分别是:From Space,To Space
- 旧域:也就是老年代
- 永久域:从配置角度看,永久域是独立于JVM的,大小为4M
程序员无法手动释放内存,只能释放引用,内存释放只能由GC释放,程序员可以手动触发GC:System.gc(), 或者是当内存不够用的时候,GC会自动启动,或者是APP空闲的时候,也会启动回收机制。
GC执行的过程:
- 新建的对象都首先存放在Eden中,如果对象太大,可能直接进入老年代,也就是旧域中。
- GC开始执行,都是从Eden或者是From Space把对象copy到To Space中,至于中间的算法,有好几种,标记算法,标记幸存次数,还有复制算法,具体怎么实现的,我不知道。当把对象移动到To Spce之后,此时的To Space变成了From Space,之前的From Space变成了To Space。然后,继续循环
- 循环一次次数之后,对象达到了移动到旧域的条件,就把对象移动到旧域。
- 最后,GC就会释放旧域的对象所占用的内存
PS:以上都是个人观点,不保证完全正确,没有漏洞。